Lab 6: Garbage Collector
Overview
In this lab, your will design and
implement a garbage collector called Gimple
(Garbage collector is simple) and link it into
your Tiger compiler, so that your compiler can manage the Java heap
in an automatic manner.
This lab consists of two parts. In the first part, you will
design and implement GC maps, including class maps for
classes and integer arrays, and stack maps for stack
frames and physical registers.
In the second part, you will design and implement the
Gimple garbage collector based on Cheney's copying algorithm.
This algorithm is easier to implement though less space-efficient.
Getting Started
First, check out the source for lab 6:
$ git commit -am 'my solution to lab5'
$ git checkout -b lab6 origin/lab6
these commands will commit your changes to lab5
branch to your local Git repository and then
create and check out the remote lab6 branch
into your local lab6 branch.
Again, you will now need to merge your code from lab5 into the
new lab6 branch:
$ git merge lab5
Do not forget to resolve any conflicts before commit to
the local lab6 branch:
$ git commit -am 'lab6 init'
Now, you can import the new lab6 code into
your favorite IDE. There
are a bunch of new files that you
should browse through:
runtime/gc.*: Gimple garbage collector
Hand-in Procedure
When you finished your lab, zip you code and submit to the
online teaching system.
Part A: GC Maps
In this lab, you will first design and implement GC maps,
which are data structures generated by compilers to aid in
garbage collectors.
The Two-Phase Abstraction
The right figure presents
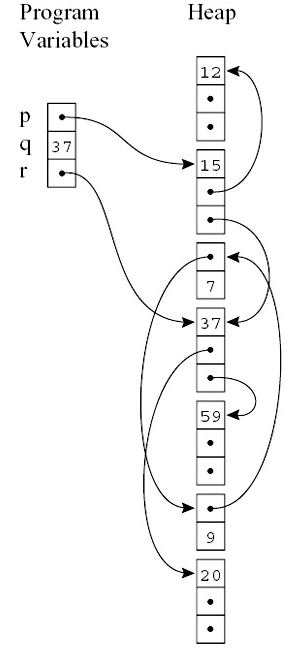 a sample Java memory layout, during the execution
of a Java application.
Conceptually, the task of a
garbage collector can be divided into two sub-phases: scanning
and collecting. During the
scanning phase, the collector scans through objects in the
heap to mark which objects are reachable whereas
which are not.
Next, during the collecting phase, the
collector will collect unreachable objects to
reclaim heap spaces.
Of course, the division of the garbage
collection into scanning and
collecting phases is more of explanation purpose.
Real-world garbage collectors might combine the two phases
or even make use of other strategies.
a sample Java memory layout, during the execution
of a Java application.
Conceptually, the task of a
garbage collector can be divided into two sub-phases: scanning
and collecting. During the
scanning phase, the collector scans through objects in the
heap to mark which objects are reachable whereas
which are not.
Next, during the collecting phase, the
collector will collect unreachable objects to
reclaim heap spaces.
Of course, the division of the garbage
collection into scanning and
collecting phases is more of explanation purpose.
Real-world garbage collectors might combine the two phases
or even make use of other strategies.
GC Maps
Before designing and implementing the garbage collector,
two problems must be answered: first, how does
the garbage collector know where to trace the pointers when
scanning an object?
Second, how does the garbage collector determine where to
start to trace the Java heap?
Taking the memory layout in the right figure as an example.
Answers to the first problem will tell the collector
to trace both the
second and third fields when scanning the object with
data 15 (in the first field).
And answers to the second problem will tell the collector
to trace the Java heap starting from program variables
p and r, instead of
q.
To answer the aforementioned problems, the garbage collector
need the detailed information about memory layouts called
GC maps.
Specifically, to tackle the first problem, the garbage collector
will need class maps recording which fields are pointers
in a given class.
To tackle the second problem, the garbage collector
will need stack maps recording which physical registers or
stack slots in a given stack frame are pointers.
The compiler is responsible for generating these GC maps.
Class GC Maps
For each class, you need to generate a class GC map
data structure
specifying the number of fields in this class as well as
pointers among them. You can use the string-based
representation for the class GC maps with a character Y
for pointer field and N otherwise.
Furthermore, to save memory occupation, you might
store the class GC map in the virtual method table instead of
in each object.
To put the above discussion into perspective, consider the
following example. The Java class A has
two pointer fields (x and z)
besides one integer field (y):
class A{
B x;
int y;
A z;
... // methods
};
The class GC map class_gc_map for A
can be placed at the first slot in the virtual method table
for A:
struct A_virtual_table{
char *class_gc_map = "YNY"; // class GC map
... // virtual method pointers as before
};
where the string "YNY" specifies length
of the object as well as type for each field.
Modify the code generator in your Tiger compiler, to generate
class GC maps for each class. You
might store the class GC map in the first field of the class'
virtual method table.
And you can set up the virtual table pointer in each
object to points to the 2nd slot of the virtual method table
(i.e., the class_gc_map resides at index -1), so that you do not
need to modify other parts of your code generator.
Is the string-based implementation of class GC map
the best strategy?
In what scenarios it is inefficient?
Can you propose a better idea for class GC map representation?
Implement your idea into your Tiger compiler.
Design an implementation strategy of class GC map
for arrays.
Implement your strategy into the Tiger compiler.
Recall that MiniJava only has integer array.
To this point, your Tiger compiler should compile all test
cases successfully and the generated binaries should run
correctly (even though your Gimple garbage collector is
still missing).
Again, do not forget to test your implementations and fix any
bugs before continuing.
Other features in full Java (e.g., type castings, array of
classes, or reflections)
might also need support from the class map.
Propose design strategy to extend the current class GC maps
to support these features, and implement your strategy into
your Tiger compiler.
Stack GC Maps
To generate stack GC maps, you will generate, for each
call site (a.k.a, safe points), a data structure recording
which stack slots and
live physical registers holding pointers.
Hence, there will be a list of N data structures
for N static call sites.
For example, consider the following sample assembly code your
Tiger compiler might generate:
f:
...
call g // a call site (to the function g) and
L_1: // ... its return address
...
call h
L_2:
...
n:
...
call k
L_3:
...
the function f contains 2 call sites with
its corresponding return address
(e.g., the function call to g with the
return address L_1), whereas the
function n has just 1 call site with
its return address.
Your Tiger compiler will generate one data fragment for each
call site, respectively:
fragment_L_1:
L_1; // the return address
slots; // stack slot offsets containing pointers
liveRegs; // registers containing live pointers
fragment_L_2:
L_2; // the return address
slots; // stack slot offsets containing pointers
liveRegs; // registers containing live pointers
fragment_L_3:
L_3; // the return address
slots; // stack slot offsets containing pointers
liveRegs; // registers containing live pointers
the field L_i (i=1, 2, or 3) records the return address
and will be used by the
garbage collector to figure out the dedicated function
for a specific return address during stack walking
(to be discussed next), the field slots records
stack slot offsets containing pointers; and the field
liveRegs records registers containing pointers
and also is live across this call.
Design concrete data structures to implement the above
data structures. It should be noted that both fields
slots and liveRegs are of variable
lengths.
One possible strategy is to use the string-based
representation as we did for the class GC maps, but
you are free to propose your own ideas and implement them
into your Tiger compiler.
Callee-saved registers pose a technical
challenge to garbage collectors
as they might contain heap pointers and might be pushed onto
the callee's stack frame.
To address this challenge, your might perform a whole call stack
analysis, from the caller to the callee, to analyze which callee-saved
registers contain pointers and in which function they are
pushed on the stack frame.
Propose an algorithm to support callee-save registers.
In the meanwhile, propose a data structure to store such
information in the stack GC maps.
Modify your Tiger compiler to generate the stack GC maps.
Our current criterion for deciding safe points, while
correct, is conservative in that we treat every
function call site as safe points.
Propose a new criterion to decide safe points more
precisely, which may save spaces the stack GC maps
occupied.
You might find constructing call graphs useful.
For real-world multithreaded
Java programs, what technical difficulties might manifest
to collect such programs?
How do you calculate stack GC maps for such programs?
How do you calculate stack GC maps for a program in
weakly typed languages (e.g., C/C+)?
Recall that, variables might always be cast into pointers due
to the lacking of strong typing in those languages.
To this point, your Tiger compiler should compile all test
cases successfully and the generated binaries should run
correctly (even though your Gimple garbage collector is
still missing).
Again, do not forget to test your implementations and fix any
bugs before continuing.
Part B: Garbage Collection
In this part of the lab, you will design and implement the
Gimple garbage collector.
You will first design and implement a
Java heap, then design an object model for MiniJava.
Next, you will build GC roots by a
call stack walking by leveraging the stack GC maps (as we have
discussion in last section).
Finally, you will implement a copying collection
based on Cheney's algorithm.
The Java Heap
In this part of the lab, you will first design a data
structure to implement a tailored Java heap, which is transparent,
flexible, and secure.
As you will use copying collection in your Gimple GC, so
the heap consists of two semi-heap of equal sizes.
Design and implement a data structure to represent Java heap.
You may use a static heap (i.e., the heap size is static)
or a dynamic one (i.e., the heap size is tunable).
Think carefully about its interface design.
GC Roots and Stack Walking
Upon a collection, the GC should first identify GC roots
by leveraging the stack GC map as you have created above.
The identification is performed by walking the call
stack to inspect each stack frame.
To be specific, suppose the stack layout just before the
GC execution is as follows:
-----------------------------------
\|/ |
------------------------------------------------------------------------> stack grows
... | ret | saved-rbp | locals | ... | ret | saved-rbp | locals | ...
-------------------------------------------------------------------------
^
rbp
You should process each stack frame as follows.
First you process the most recent stack frame (i.e., the
rightmost one) by fetching
the return address ret, and use it as the key to index
into the stack GC maps to figure out the corresponding
map for the return address ret.
You obtain, from the target map, the detailed stack layout
for the target frame, telling where pointers reside.
Similarly, you walk the call stack to the next
stack frame to repeat the above process, until exhausting
the whole call stack.
As the result of this stack walking, you create a list of all
GC roots to be scanned.
Design and implement a data structure to represent GC roots.
Then implement the above stack walking into your Tiger
collector to identify all GC roots.
To this point, your Tiger compilers should compile all
test cases successfully. Fix any bugs before continuing.
The stack walking is inherently machine dependent as it
will walk the low-level call stack.
Suppose that your Tiger compiler is generating code for
a different ISA (e.g., AArch64 or RISC-V), which part of
the stack GC map data structure as well as the stack walking
strategy should be modified?
Can you propose a machine-independent API to hide the
machine discrepancies effectively?
Object Model
An object model encodes the strategy that
how an object can be laid out in the memory (the heap).
A good object model should support all kinds of possible
operations efficiently and conveniently
on an object: virtual method dispatching, locking, garbage
collection, and so on.
Meanwhile, the object model should encode an object as compact
as possible to save memory spaces.
In previous labs, you have used a simple yet effective
object model for normal objects and (integer)
array objects in MiniJava.
In this lab, you will extend the object model to support
garbage collection. To be specific, you might use
the following object model with 4 extra fields as the
object header:
struct object{
void *vptr; // virtual method table pointer
long isObjOrArray; // is this a normal object or an (integer) array object?
long length; // array length
void *forwarding; // forwarding pointer, will be used by your Gimple GC
...; // normal fields for class or array
};
the first field vptr is a virtual method table
pointer pointing to the class virtual method table, to
support virtual method dispatching;
the second field isObjOrArray
indicates whether the target object is a normal object or an
array; the third field length records
the length of the array (if the target object is indeed
an array); finally, the fourth field forwarding
is a special pointer which will be used by your Gimple GC.
You are free to modify or extend this representation, or
propose your own representation.
Modify the functions Tiger_new() and
Tiger_newIntArray() in garbage collector,
to make use of this new object model.
You might also need to change your code generator
of your Tiger compiler to reflect the
changes of the object model.
The object model you have been using so far, though simple and
easy to implement, may waste memory space for small objects
due to the object header space occupation.
Can you design and implement a fancier
object model to reduce the size of the object header?
Can you use just one, instead of 4 machine words, to
represent the header?
Design an object model to support other features in full Java:
virtual method dispatching, multi-threading, locking,
garbage collection, interface methods, and hashing, among others.
You can take a look at
this article
and
this paper
to start with.
Copying Collection
In this part, you are going to implement the garbage collector,
based on
Cheney's
algorithm using a breadth-first strategy.
You should read Tiger book chapter 13.3 first, if you have not
read the algorithm.
Implement the copying collector in the function
Tiger_gc() in the file runtime/gc.c.
Suppose you are collecting garbages for programs
in unsafe languages like C/C++, can you still use
a copying collection strategy as the Cheney's algorithm?
What challenges might you face?
Propose ideas to address these potential challenges.
To compile multithreaded programs (e.g., full Java), what
changes should be made to the collection algorithm?
Implement your idea into your collector.
Hint, you may implement a simple concurrent
collector where the Java program is still single-threaded,
that is, a programs consists of two threads: Java application
and the collector. How to coordinate these two threads?
What other challenges
your collector might face brought by other features
of Java (e.g., locking or finalization?)?
And how do you address these challenges?
To this point, you should have a working Tiger compiler
with a full-fledged garbage collector. Do not forget
to test your compiler as well as collector.
Your Gimple GC implemented so far runs silently behind
the application.
In order to improve its observability, you might
instrument your GC to record and output useful statistical
information. For example, when
your application runs, besides the normal output, your Gimple GC
can also output log information like:
GC round 1: time 0.3s, collected 512 bytes, heap size 10223 bytes
GC round 2: time 0.2s, collected 128 bytes, heap size 14567 bytes
GC round 3: time 0.8s, collected 4096 bytes, heap size 18979 bytes
...
presenting the GC round number, time taken, the collected bytes,
and remaining heap size for each round of GC, respectively.
Implement this feature into your Gimple collector.
You can further improve your Gimple GC in various ways.
The following are some ideas worthy trying, but, nevertheless,
you are encouraged to propose your own ideas and implement them.
Propose your own ideas to improve your Gimple GC. For instance:
-
Implement an incremental, generational, or
concurrent GC and link it into your Tiger compiler.
-
Implement a heap visualizor,
like visualvm
or GC spy.
-
Implement a source-level heap profiler.
Hand-in
This completes the lab. Remember to hand in your solution to
the online teaching system.