A shell is software that provides an interface for users of an operating system to provide access to the services of kernel. On Unix-based or Linux-based operating systems, a shell can be invoked through the shell command in the command line interface, allowing users to direct operations through computer commands, texts, or scripts.
In this lab, you will implement a minimal shell similar to the shell on Linux. The mini shell supports not only basic commands (e.g., ls, cat, grep, wc, and sleep), but also compound commands (e.g., pipe, sequential execution, background, and redirection).
When you finished the lab, zip your code files with the file name student ID-lab-2.zip (e.g., SA19225789-lab-2.zip) and submit it to the Online Teaching Platform. The deadline is 23:59, Oct. 13, 2023 (Beijing time). Any late submission will NOT be accepted.
In this section, let us start by learning what a shell is, by going through its basic usage. Conceptually, a shell is an ordinary program that reads inputs representing commands from the user, and executes them accordingly. In Ubuntu, the basic graphical interface looks like the figure below.
css-lab@tiger:~$
In computer programming and operating system, "basic commands" typically refer to a set of core commands or operations that provide users or programmers with the ability to perform fundamental tasks such as file operations, data input/output, and system control. In a Linux Shell environment, basic commands include operations like lsls (list directory contents), catcat (concatenate and display file contents), and echo (output text or variables), among others. These commands form the foundation for user interaction with the Linux operating system and also serve as the building blocks for Shell script programming.
The ls (list) command lists all files and folders in your current working directory. You can also specify paths to other directories if you want to view their contents.
For example, to list files in the current directory, we can run:
css-lab@tiger:~$ ls
index.html labs resources.html sampleCode schedule.html slides
The cat (short for “concatenate“) command is one of the most frequently used commands in Linux/Unix-like operating systems. This command allows us to create single or multiple files, view contents of a file, concatenate files, and redirect output in terminal or files.
The syntax for the cat command is:
cat [options] [file]
For example: the following command will display the contents of the a.txt file in the shell.
css-lab@tiger:~$ cat a.txt
Welcome to system programming in C!
In Linux, compound commands are advanced constructs that combine two or more basic commands to perform more complex operations. Compound commands can utilize various elements like control structures and operators to facilitate intricate tasks. For instance, Pipe Sequence (|) allows the output of one command to be used as the input for another, as in ls | grep 'txt'. Background (&) lets a command run in the background, freeing up the terminal for other tasks, as in sleep 10 &. Redirection allows you to redirect the output or input of commands to and from files, such as echo "Hello" > hello.txt. These compound commands greatly enhance the flexibility and power of Linux Shell scripting and command-line interaction.
The pipe command combines two or more commands to redirect their IOs. Generally, the syntax for pipe is:
command 1 | command 2 | command 3 |...
where the output of the command 1 is used as the input for the command 2. In turn, the output of command 2 is used as the input of command 3, and so on. For example, suppose we have a file named name.txt containing student names:
css-lab@tiger:~$ cat name.txt
Alice
Lamda
John
Mike
Bob
Then, to sort this file, we use a pipe:
css-lab@tiger:~$ cat name.txt | sort
Alice
Bob
John
Lamda
Mike
where the output of the command cat is fed to the command sort.
How to run two or more terminal commands at once, but one by one? The semicolon ; operator allows us to execute multiple commands in succession.
The general syntax for sequence is:
command 1; command 2; command 3; ...
For example, the command:
css-lab@tiger:~$ ls; pwd; whoami
index.html labs resources.html sampleCode schedule.html slides
/home/css-lab
css-lab
will give us a listing of the current directory (ls), find out the directory you are currently in (pwd), and display your login name (whoami) all at once.
Typically, when you run a command in the terminal, you have to wait until the command finishes before you can enter another one. This is often called running the command in the foreground or foreground process. When a process runs in the foreground, it occupies your shell.
What if the command takes a long time to finish, and you want to run other commands in the meanwhile? You have several options at your disposal. The most obvious and straightforward option is to start a new shell session and run the command in it. Another option is to run the command in the background (thus, the process is called a background process).
A background process is a process/command that is started from a terminal and runs in the background, without interaction from the user.
To run a command in the background, add the ampersand symbol (&) at the end of the command with this syntax:
command &
For example, you can run:
css-lab@tiger:~$ gedit &
css-lab@tiger:~$
to start the gedit text editor from your terminal, running as a background process.
Redirection is a feature allows us to change the standard input/output device, when executing a command.
The general syntax for output redirection is:
command > file
which redirects the standard output to the file.
For example, the command
css-lab@tiger:~$ ls > listing
css-lab@tiger:~$ cat listing
files.txt
index.html
labs
resources.html
sampleCode
schedule.html
slides
will redirect the output of command ls to a file “listing”, instead of to your screen (that is, the stdout).
As Figure 1.1 shows, Unix takes the traditional form of a kernel, a special program that provides services to running programs. Each running program, called a process, has memory containing instructions, data, and a stack. The instructions implement the computation of program. The data are the variables on which the computation acts. The stack organizes the procedure calls of program. A given computer typically has many processes but only a single kernel.
When a process needs to invoke a kernel service, it invokes a system call, one of the calls in the operating system interface. The system call enters the kernel; the kernel performs the service and returns. Hence, a process alternates between executing in user space and kernel space.
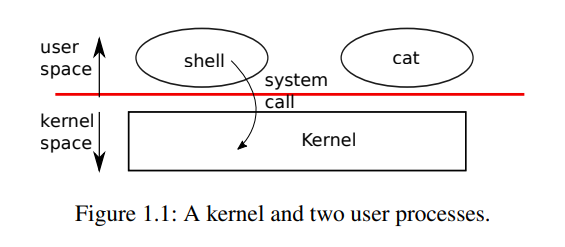
The shell is an ordinary program that reads commands from the user and executes them. The fact that the shell is a user program, and not part of the kernel, illustrates the power of the system call interface: there is nothing special about the shell. It also means that the shell is easy to replace; as a result, modern Unix systems have a variety of shells to choose from, each with its own user interface and scripting features.
When a process is not executing, the operating system saves its CPU registers, restoring them when it next runs the process. The kernel associates a process identifier, or PID, with each process.
A process may create a new process using the fork system call. Fork gives the new process exactly the same memory contents (both instructions and data) as the calling process. Fork returns in both the original and new processes. In the original process , fork returns the PID of new process . In the new process, fork returns zero. The original and new processes are often called the parent and child.
For example, consider the following program fragment written in the C programming language:
int pid = fork();
if(pid > 0){
printf("parent: child=%d\n", pid);
pid = wait((int *) 0);
printf("child %d is done\n", pid);
} else if(pid == 0){
printf("child: exiting\n");
exit(0);
} else {
printf("fork error\n");
}
The exec system call replaces the memory of calling process with a new memory image loaded from a file stored in the file system. The file must have a particular format, which specifies which part of the file holds instructions, which part is data, at which instruction to start, etc. When exec succeeds, it does not return to the calling program; instead, the instructions loaded from the file start executing at the entry point declared in the ELF header. Exec takes two arguments: the name of the file containing the executable and an array of string arguments. For example:
char *argv[3];
argv[0] = "echo";
argv[1] = "hello";
argv[2] = 0;
exec("/bin/echo", argv);
printf("exec error\n");
This fragment replaces the calling program with an instance of the program /bin/echo running with the argument list /bin/echo. Most programs ignore the first element of the argument array, which is conventionally the name of the program.
The shell uses the above calls to run programs on behalf of users. The main structure of the shell is simple; see main (src/main.c). The main loop reads a line of input from the user . Then it analyzes the input from the user with yyparse. Then it calls fork, which creates a copy of the shell process. The parent calls wait, while the child runs the command. For example, if the user had typed “echo hello” to the shell, yyparse would have been called with “echo hello” as the argument. Cmd_run (src/ast.c) runs the actual command. For “echo hello”, it would call execv (src/ast.c). If execv succeeds then the child will execute instructions from echo instead of Cmd_run. At some point echo will call exit, which will cause the parent to return from wait in main (user/sh.c:145).
A file descriptor is a small integer representing a kernel-managed object that a process may read from or write to. A process may obtain a file descriptor by opening a file, directory, or device, or by creating a pipe, or by duplicating an existing descriptor. For simplicity, we will often refer to the object a file descriptor refers to as a “file”; the file descriptor interface abstracts away the differences between files, pipes, and devices, making them all look like streams of bytes. We will refer to input and output as I/O.
Every process has a private space of file descriptors starting at zero. By convention, a process reads from file descriptor 0 (standard input), writes output to file descriptor 1 (standard output), and writes error messages to file descriptor 2 (standard error). As we will see, the shell exploits the convention to implement I/O redirection and pipelines.
The read and write system calls read bytes from and write bytes to open files named by file descriptors. The call reads at most n bytes from the file descriptor fd, copies them into buf, and returns the number of bytes read. Each file descriptor that refers to a file has an offset associated with it. Read reads data from the current file offset and then advances that offset by the number of bytes read: a subsequent read will return the bytes following the ones returned by the first read. When there are no more bytes to read, read returns zero to indicate the end of the file.
The call write(fd, buf, n) writes n bytes from buf to the file descriptor fd and returns the number of bytes written. Fewer than n bytes are written only when an error occurs. Like read, write writes data at the current file offset and then advances that offset by the number of bytes written: each write picks up where the previous one left off.
The following program fragment (which forms the essence of the program cat) copies data from its standard input to its standard output. If an error occurs, it writes a message to the standard error.
char buf[512];
int n;
for(;;){
n = read(0, buf, sizeof buf);
if(n == 0)
break;
if(n < 0){
fprintf(2, "read error\n");
exit(1);
}
if(write(1, buf, n) != n){
fprintf(2, "write error\n");
exit(1);
}
}
The important thing to note in the code fragment is that cat does not know whether it is reading from a file, console, or a pipe. Similarly, cat does not know whether it is printing to a console, a file, or whatever. The use of file descriptors and the convention that file descriptor 0 is input and file descriptor 1 is output allows a simple implementation of cat.
The close system call releases a file descriptor, making it free for reuse by a future open, pipe, or dup system call (see below). A newly allocated file descriptor is always the lowest-numbered unused descriptor of the current process.
File descriptors and fork interact to make I/O redirection easy to implement. Fork copies the file descriptor table of memory along with its memory, so that the child starts with exactly the same open files as the parent. The system call exec replaces the memory of calling process but preserves its file table. This behavior allows the shell to implement I/O redirection by forking, re-opening chosen file descriptors in the child, and then calling exec to run the new program. Here is a simplified version of the code a shell runs for the command cat < input.txt :
char *argv[2];
argv[0] = "cat";
argv[1] = 0;
if(fork() == 0) {
close(0);
open("input.txt", O_RDONLY);
exec("cat", argv);
}
Although fork copies the file descriptor table, each underlying file offset is shared between parent and child. Consider this example:
if(fork() == 0) {
write(1, "hello ", 6);
exit(0);
} else {
wait(0);
write(1, "world\n", 6);
}
At the end of this fragment, the file attached to file descriptor 1 will contain the data hello world. The write in the parent (which, thanks to wait, runs only after the child is finished) picks up where the write of child left off. This behavior helps produce sequential output from sequences of shell commands, like (echo hello; echo world) >output.txt .
The dup system call duplicates an existing file descriptor, returning a new one that refers to the same underlying I/O object. Both file descriptors share an offset, just as the file descriptors duplicated by fork do. This is another way to write hello world into a file:
fd = dup(1);
write(1, "hello ", 6);
write(fd, "world\n", 6);
Two file descriptors share an offset if they were derived from the same original file descriptor by a sequence of fork and dup calls. Other file descriptors do not share offsets, even if they resulted from open calls for the same file.
File descriptors are a powerful abstraction, because they hide the details of what they are con-nected to: a process writing to file descriptor 1 may be writing to a file, to a device like the console, or to a pipe.
A pipe is a small kernel buffer exposed to processes as a pair of file descriptors, one for reading and one for writing. Writing data to one end of the pipe makes that data available for reading from the other end of the pipe. Pipes provide a way for processes to communicate.
The following example code runs the program wc with standard input connected to the read end of a pipe.
int p[2];
char *argv[2];
argv[0] = "wc";
argv[1] = 0;
pipe(p);
if(fork() == 0) {
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
exec("/bin/wc", argv);
} else {
close(p[0]);
write(p[1], "hello world\n", 12);
close(p[1]);
}
The program calls pipe, which creates a new pipe and records the read and write file descriptors in the array p. After fork, both parent and child have file descriptors referring to the pipe. The child calls close and dup to make file descriptor zero refer to the read end of the pipe, closes the file descriptors in p, and calls exec to run wc. When wc reads from its standard input, it reads from the pipe. The parent closes the read side of the pipe, writes to the pipe, and then closes the write side.
If no data is available, a read on a pipe waits for either data to be written or for all file descriptors referring to the write end to be closed; in the latter case, read will return 0, just as if the end of a data file had been reached. The fact that read blocks until it is impossible for new data to arrive is one reason that it is important for the child to close the write end of the pipe before executing wc above: if one of the file descriptors of wc referred to the write end of the pipe, wc would never see end-of-file.
In our lab, we can implement pipelines such as grep fork ast.c | wc -l similar to the above code . The child process creates a pipe to connect the left end of the pipeline with the right end. Then it calls fork and Cmd_run for the left end of the pipeline and fork and Cmd_run for the right end, and waits for both to finish. The right end of the pipeline may be a command that itself includes a pipe (e.g., a | b | c), which itself forks two new child processes (one for b and one for c). Thus, the shell may create a tree of processes. The leaves of this tree are commands and the interior nodes are processes that wait until the left and right children complete.
We can use temporary files to achieve functions similar to pipes. For example, the pipeline
css-lab@tiger:~$ echo hello world | wc
could be implemented without pipes as
css-lab@tiger:~$ echo hello world >/tmp/xyz; wc </tmp/xyz
To implement this shell, firstly, we need to read a line of input from the user and save the command in a suitable data structure. Then we need to execute it.
This experiment requires the installation of flex and bison. Please refer to lab0 for the installation process.
Download the source code and unzip. This source code is incomplete, you need to fill in the correct code blocks so that the shell can execute the command correctly.
Let us see ast.h. First define an enumerated type, listing the types of five commands supported by our shell. Then define five structs, corresponding to the basic command and four compound commands, sequential execution, background, redirection, pipe. In addition, this file also declares five functions:
Cmd_t Cmd_Atom_new(struct node *);
Cmd_t Cmd_Seq_new(Cmd_t left, Cmd_t right);
Cmd_t Cmd_Back_new(Cmd_t back);
Cmd_t Cmd_Pipe_new(Cmd_t left, Cmd_t right);
Cmd_t Cmd_Redir_new(Cmd_t left, Cmd_t right, int fd);
The role of these functions is to use arguments to construct the five structs defined above. These functions are called in the process of parsing commands(parser.y). After the parsing process is over, the information in the command is stored in an abstract syntax tree composed of structs.
For example, for this command:
css-lab@tiger:~$ cat hello.txt | grep -n hello > c.txt
In the main.c, after calling the yyparse(), We can get an abstract syntax tree(AST), the simplified structure is as follows:
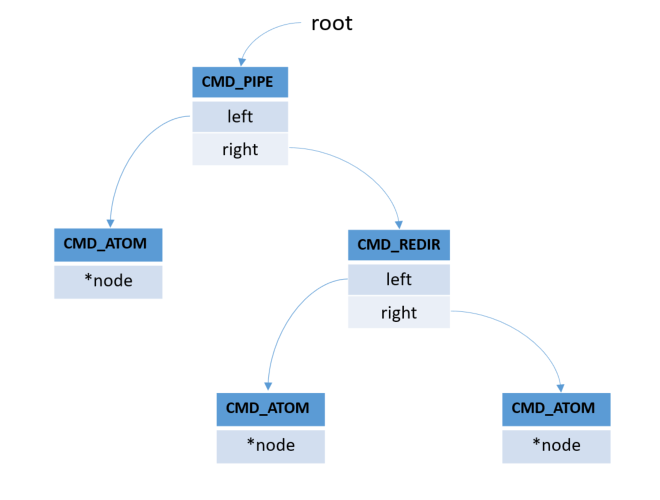
The leaves of this AST are basic commands. The variable root is a pointer to the root node of the abstract syntax tree.
Function void Cmd_print(Cmd_t cmd) can print out the commands read by the shell, and Function void Cmd_run(Cmd_t cmd) will execute the commands read by the shell.
In the file ast.c, we have given the construction function of leaf nodes (e.g., Cmd_t Cmd_Atom_new(struct node *)) and a construction function of internal nodes (e.g., Cmd_t Cmd_Seq_new(struct Cmd_t *left, struct Cmd_t *right)).
Cmd_t Cmd_Back_new(Cmd_t back);
Cmd_t Cmd_Pipe_new(Cmd_t left, Cmd_t right);
Cmd_t Cmd_Redir_new(Cmd_t left, Cmd_t right, int fd);
Hint: you can refer to the data structure defined
in the file ast.h.
The function void Cmd_print(Cmd_t cmd) will print out the commands entered by the user, solely to check whether the abstract syntax tree (AST) is constructed correctly.
Finally, compile and run the project, then use the following test cases to check whether your solution is correct.
css-lab@tiger:~$ cat hello.txt | grep -n hello > c.txt ; ls -l
css-lab@tiger:~$ sleep 10 &
css-lab@tiger:~$ cat hello.txt > c.txt
Then call void Cmd_run(Cmd_t cmd)
in main.c and comment out
Cmd_print(root).
Finally, compile and run the project, and
use the following test cases to justify your
answer.
css-lab@tiger:~$ cat hello.txt | grep -n hello>c.txt; cat c.txt; ls
Before entering the command, create a file called
hello.txt
in the current working directory. The content of
the file is as follows:
hello
hello;
hello world!
Next, enter the following command:
css-lab@tiger:~$ sleep 10 &
what do you observe?
Happy hacking!